CAP Theorem: Availability vs consistency
CAP Theorem, Availability and Consistency Patterns Explained..!!


Availability vs consistency
CAP theorem

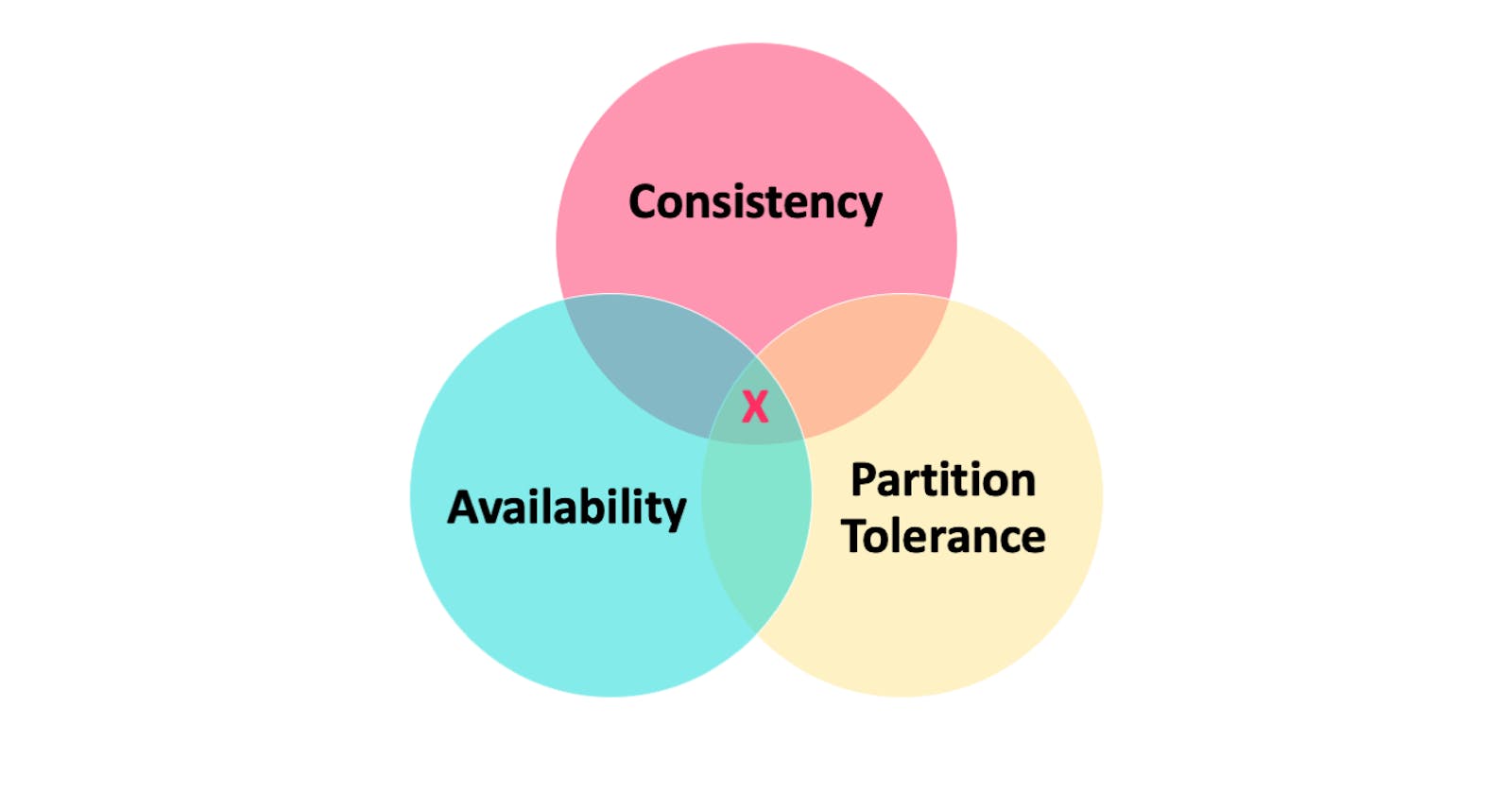
In a distributed computer system, you can only support two of the following guarantees:
- Consistency - Every read receives the most recent write or an error
- Availability - Every request receives a response, without guarantee that it contains the most recent version of the information
- Partition Tolerance - The system continues to operate despite arbitrary partitioning due to network failures
Networks aren't reliable, so you'll need to support partition tolerance. You'll need to make a software tradeoff between consistency and availability.
CP - consistency and partition tolerance
Waiting for a response from the partitioned node might result in a timeout error. CP is a good choice if your business needs require atomic reads and writes.
AP - availability and partition tolerance
Responses return the most recent version of the data available on a node, which might not be the latest. Writes might take some time to propagate when the partition is resolved.
AP is a good choice if the business needs allow for eventual consistency or when the system needs to continue working despite external errors.
Consistency patterns
With multiple copies of the same data, we are faced with options on how to synchronize them so clients have a consistent view of the data. Recall the definition of consistency from the CAP theorem - Every read receives the most recent write or an error.
Weak consistency
After a write, reads may or may not see it. A best effort approach is taken.
This approach is seen in systems such as memcached. Weak consistency works well in real time use cases such as VoIP, video chat, and realtime multiplayer games. For example, if you are on a phone call and lose reception for a few seconds, when you regain connection you do not hear what was spoken during connection loss.
Eventual consistency
After a write, reads will eventually see it (typically within milliseconds). Data is replicated asynchronously.
This approach is seen in systems such as DNS and email. Eventual consistency works well in highly available systems.
Strong consistency
After a write, reads will see it. Data is replicated synchronously.
This approach is seen in file systems and RDBMSes. Strong consistency works well in systems that need transactions.
Availability patterns
There are two main patterns to support high availability: fail-over and replication.
Fail-over
Active-passive
With active-passive fail-over, heartbeats are sent between the active and the passive server on standby. If the heartbeat is interrupted, the passive server takes over the active's IP address and resumes service.
The length of downtime is determined by whether the passive server is already running in 'hot' standby or whether it needs to start up from 'cold' standby. Only the active server handles traffic.
Active-passive failover can also be referred to as master-slave failover.
Active-active
In active-active, both servers are managing traffic, spreading the load between them.
If the servers are public-facing, the DNS would need to know about the public IPs of both servers. If the servers are internal-facing, application logic would need to know about both servers.
Active-active failover can also be referred to as master-master failover.
Disadvantages: failover
- Fail-over adds more hardware and additional complexity.
- There is a potential for loss of data if the active system fails before any newly written data can be replicated to the passive.
Thank you for reading
If you like what you read and want to see more, please support me with coffee or a book ;)
