Elastic Search Scaling Strategies


Elastic Search Scaling Strategies
Scaling your Elastic Search Cluster might seem easy enough to add nodes to a cluster to increase the performance, but this is actually a case where a bit of planning goes a long way toward getting the best performance out of your cluster.
Every use of Elastic search is different, so you’ll have to pick the best options for your cluster based on how you’ll index data, as well as how you’ll search it. In general, there are at least two things that need to be considered when planning for production Elastic Search Cluster.
- Over-sharding
- Maximizing Throughput
Over-sharding
Over-sharding is the process whereby you intentionally create a larger number of shards for an index so you have room to add nodes and grow in the future. Let’s look at the following example.
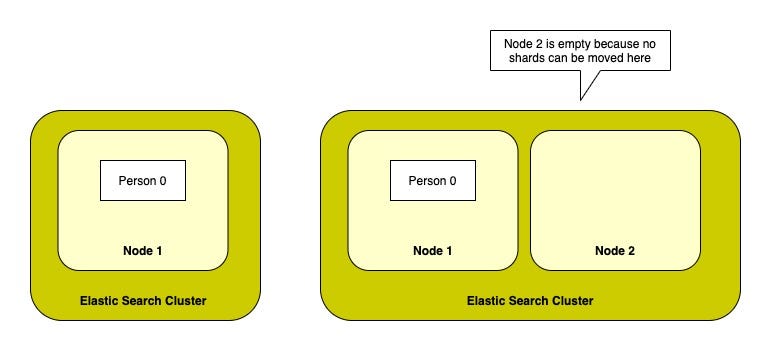
We created Person index in single node cluster with no_of_shards = 1 and no_of_replicas = 0.
But what happens when you add another node to the cluster? We won’t get any benefit by adding new nodes in this scenario because we are unable to scale the indexing and querying load as it still will be handled by only node (Node 1) which has single shard.
We should always make sure to have at least primary shards in cluster as we plan to have nodes.
If we have 11 primary shards for 5 node cluster we have room to grow when we need to add more nodes and to handle more load. Considering the same example, if you need more than 11 nodes, we won’t be able to distribute your primary shards across nodes because we’ll have more nodes than shards.
Now i will just create an index with 100 primary shards so i can scale out my cluster whenever i want. It may seem like a good idea at first, but there’s a hidden cost to each shard Elastic-search has to manage. Because each shard is a complete Lucene index and it requires a number of file descriptors for each segment of the index, as well as a memory overhead.
- By creating too large a number of shards for an index, could end up hitting the machine’s file descriptor or RAM limits.
- In addition, when compressing your data, we’ll end up splitting the data across 100 different things, lowering the compression rate we would have gotten if we had picked a more reasonable size.
There is no perfect shard-to-index ratio for all use cases. Elastic search picks a good default of five shards for the general case, but it’s always important to think about how you plan on growing (or shrinking).
Once an index has been created with a number of shards, the number of primary shards can never be changed for that index!
Maximizing Throughput
There are two use cases where we need to think about Maximizing throughput.
- Write Heavy Applications (More Index requests)
- Read Heavy Applications (More Search Requests)
Write Heavy Applications (More Index requests):
If there are thousands of new groups and events, how would you go about indexing them as fast as possible?
One way to make indexing faster is to temporarily reduce the number of replica shards in cluster. When indexing data, by default the request won’t complete until the data exists on the primary shard as well as all replicas, so it may be advantageous to reduce the number of replicas to one (or zero if you’re okay with the risk) while indexing and then increase the number back to one or more once the period of heavy indexing has completed.
Read Heavy Applications (More Search Requests):
Searches can be made faster by adding more replicas because either a primary or a replica shard can be used to search on. So, adding more replicas and scaling out the cluster by adding nodes will help in handling more search requests.
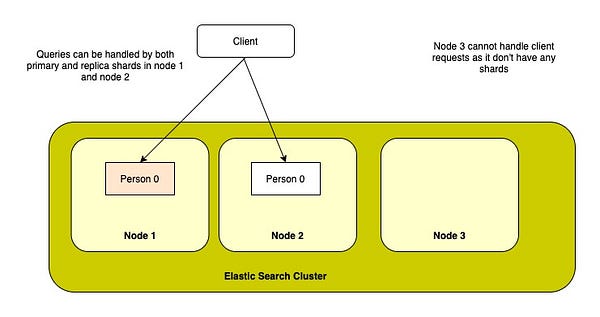
Scaling Out — Person Index with one primary and one replica shard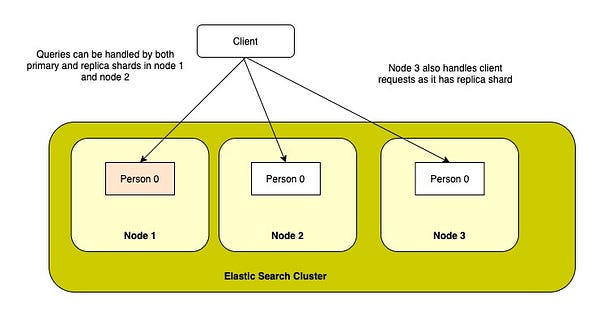
Scaling Out — Person Index with one primary and two replica shards